I fine-tuned a LLM into news summarization reasoning model
Table of Contents
I have always wanted to write about this, but I’ve recently been busy with work and life events. Over the past few months, I’ve been playing around with LLM fine-tuning using different tools like Unsloth and Axolotl for achieving different purposes, mainly for learning and fun.
The most recent one is a reasoning model focusing on bullet points news summarization. I decided to write a blog about it because this model is the model that I have spent the most money on (so far).
Why fine-tuning a model?
Even though the SOTA models now are very good and relatively cheap (not the GPT-4.5 API that costs $150 per million output token), they are running on the cloud and someone else’s computer. For stuff that is sensitive in nature, I prefer something that is running locally. Plus, I find it interesting to fine-tuning a model to suit my specific use-case.
Smaller models are able to fit in my local compute but they often lack knowledge and are generally weaker. I planned to fine-tune the smaller models to excel in 1 specific task. For this blog post, I am focusing on my news summarization use case and how I fine-tuned a small model (Llama 3.1 8b) to give a better result.
Datasets
Fine-tuning, especially supervised ones, requires dataset to begin with. In my earliest fine-tunings, I mainly searched for relevant public datasets that are available on HuggingFace.
For summarization, there are many existing datasets that are ready to grab. However, I’ve decided to create my own dataset by distilling the outputs from bigger reasoning models (i.e., DeepSeek R1 and QwQ 32b), mainly for the following reasons:
- I want my summarization in specific formats. (e.g., number of points, word, output language, etc.)
- I want a reasoning model (controllable via system prompt), even though it’s definitely overkill for this particular use case.
- I want to try knowledge distillation.
Preparing the input and output
So, I began this round of money-burning fine-tuning by knowledge distillation. I was using black box distillation, where I took a prompt, fed it into the large models (R1 or QwQ), recorded the output and fed it into the smaller model for learning.
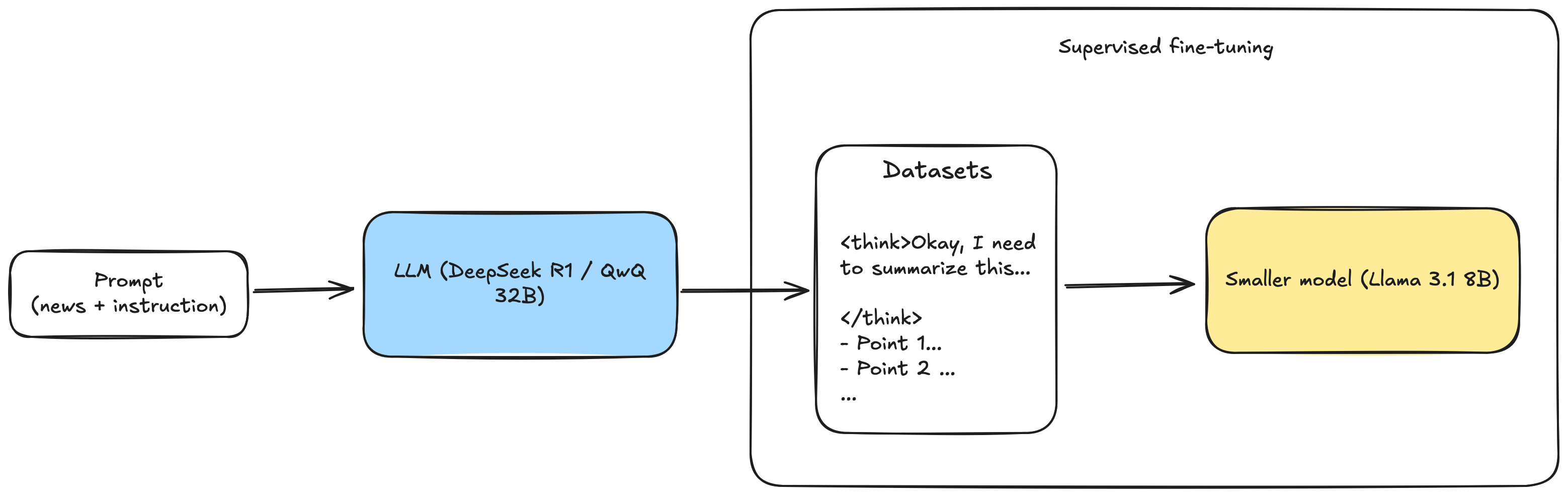
Even though the model weights are available, I decided to use black box distillation because it was the easiest option for me.
For the larger models, I used hosting providers such as fireworks.ai and DeepSeek platform. I also took the opportunity of the discounted pricing on the DeepSeek platform for non-peak hours (12.30 AM - 8.30 AM GMT+8).
The news content was crafted from the following datasets, each with its own weightage:
- liswei/news-collection-zhtw (10k randomly selected articles)
- argilla/news-summary (10k randomly selected articles)
- gopalkalpande/bbc-news-summary (all articles)
This ended up being a multi-language dataset that aligned with my goal of generating the summary based on the input language. News in English should generate a summary in English, and news in Chinese should generate a summary in Chinese.
I ended up pumping ~17 million tokens into the large models and getting ~24 million from the response, translating into $35. The dataset is now open-source on HuggingFace.
Convert into JSONL
The tool that I used, Axolotl, supports a variety of dataset formats, and I opted for the chat template because that’s what I usually use in LLM. I randomly sampled 40% of the data to be non-reasoning by omitting the reasoning traces from the response and setting the system prompt to “reasoning off”. The remaining 60% have the full reasoning traces + summary, with the system prompt set to “reasoning on”.
Below is a sample JSONL:
# reasoning on
{"messages": [{"role": "system", "content": "reasoning on"},{"role": "user", "content": "Summarize the following into bullet points,..."},{"role": "assistant", "content": "<think>Okay, I need to...</think>\n-The..."}]}
# reasoning off
{"messages": [{"role": "system", "content": "reasoning off"},{"role": "user", "content": "Summarize the following into bullet points,..."},{"role": "assistant", "content": "-The..."}]}
Supervised Fine-Tuning
I wanted to explore different tools, and it was my first time using Axolotl. The previous attempts used Unsloth, and it was pretty amazing. In contrast, Axolotl needs a config.yml that defines all training configurations, such as LoRA rank, learning rate, dataset, etc. Here’s mine for reference; the full config is available at the model card.
load_in_8bit: true
adapter: lora
lora_model_dir:
lora_r: 16
lora_alpha: 32
lora_dropout: 0.05
gradient_accumulation_steps: 4
micro_batch_size: 2
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
warmup_ratio: 0.05
I decided to load the model in 8-bit during training because:
- It reduces the VRAM usage
- I will mostly load the model in 8-bit during inference
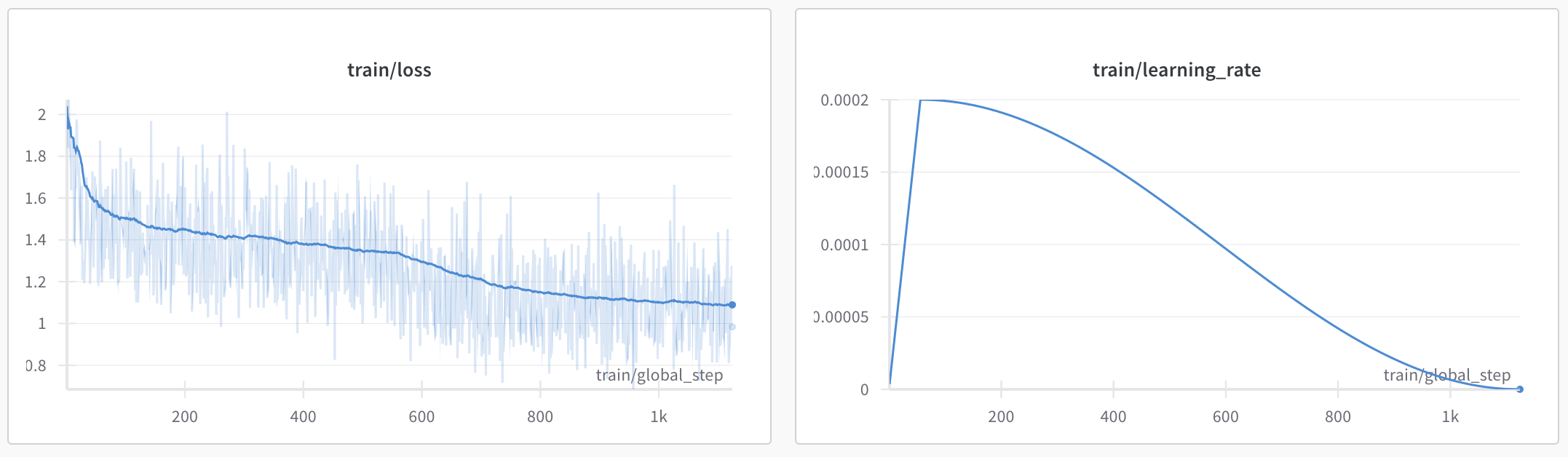
I trained the model for 2 epochs on a single H100, which took around 5.5 hours. Here are the related graphs on WandB.
Comparison
My fine-tuned model is now available for inference on featherless.ai!
For comparison, I used the hosted version of both models (mine and the original Llama 3.1 8B) on featherless.ai. Both models were evaluated using the same sampling parameters:
- Temperature: 0.3
- Top P: 1
- Min P: 0
- Rep Penalty: 1.1
Note that the models were loaded with FP8 precision.
The news was taken randomly from the following sites, covering both English and Chinese languages:
And the user prompt:
Summarize the following into 5 bullet points, each at 20 words max. Maintain the source language.
{news_content}
For news source 1:
Original:
Fine-tuned:
For news source 2:
Original:
Fine-tuned:
For news source 3:
Original:
Fine-tuned:
I found that the fine-tuned version of the model captured more details in the content while following the instructions (output language, word limit, etc.). The original model outputted extra words on top of the summarization, capturing fewer details and outputting the wrong language.
The conciseness of the fine-tuned model slightly degraded the response’s readability compared to the original model. For content that was less familiar to me, I needed to spend more effort on reading instead of just glancing through.
Of course, the evaluation was highly personal and might be subject to the IKEA effect, so take it with a grain of salt. Let me know what you think via a DM.
Aside from news summarization, I also tried the reasoning capability on other topics. Surprisingly, the thinking tokens were present in the response as long as I had the “reasoning on” system prompt.
What’s next
There are new things popping out every week in AI and I don’t have much time (and budget) to try all of them. I mostly pick something that’s interesting or something that suits my use case to hands-on. For this topic, though, perhaps I will try adding reinforcement learning after the SFT step somewhere in the future.